【Lucene】使用EasyUI和JQuery配合Lucene实现数据的分页查询以及高亮显示
本文共 11312 字,大约阅读时间需要 37 分钟。
在这里我们需要使用第三方工具将集合转换为JSON,以及用到组件BeanUtils,所以我们需要导入相应的jar包
然后导入JQuery和EasyUI相关js文件
并将EasyUI中的themes文件夹拷到WebRoot
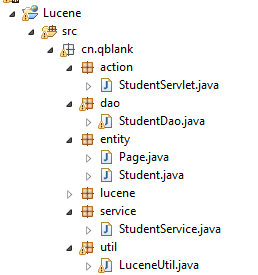
包的结构图如下:
然后我们创建一个实体类Student
package cn.qblank.entity;public class Student { private Integer id; private String name; private String describe; public Student(){} public Student(Integer id, String name, String describe) { super(); this.id = id; this.name = name; this.describe = describe; } public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getDescribe() { return describe; } public void setDescribe(String destcribe) { this.describe = destcribe; } @Override public String toString() { return "编号:" + id + "\n" + "姓名:" + name +"\n" + "简历:" + describe; }} 然后我们创建Page类,用于存储页面的属性:当前页面、每页显示记录数、总记录数、总页数
package cn.qblank.entity;import java.util.ArrayList;import java.util.List;public class Page { private Integer currPageNO;//当前页号 private Integer perPageSize = 2;//每页显示记录数,默认为2条 private Integer allRecordNO;//总记录数 private Integer allPageNO;//总页数 private List studentList = new ArrayList ();//内容 public Page(){} public Integer getCurrPageNO() { return currPageNO; } public void setCurrPageNO(Integer currPageNO) { this.currPageNO = currPageNO; } public Integer getPerPageSize() { return perPageSize; } public void setPerPageSize(Integer perPageSize) { this.perPageSize = perPageSize; } public Integer getAllRecordNO() { return allRecordNO; } public void setAllRecordNO(Integer allRecordNO) { this.allRecordNO = allRecordNO; } public Integer getAllPageNO() { return allPageNO; } public void setAllPageNO(Integer allPageNO) { this.allPageNO = allPageNO; } public List getStudentList() { return studentList; } public void setStudentList(List studentList) { this.studentList = studentList; } } 写好工具类LuceneUtil
package cn.qblank.util;import java.io.File;import java.lang.reflect.Method;import org.apache.commons.beanutils.BeanUtils;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.standard.StandardAnalyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.Field.Index;import org.apache.lucene.document.Field.Store;import org.apache.lucene.index.IndexWriter.MaxFieldLength;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.apache.lucene.util.Version;/** * Lucene工具类 * @author Administrator * */public class LuceneUtil { private static Directory directory ; private static Analyzer analyzer ; private static Version version; private static MaxFieldLength maxFieldLength; static{ try { directory = FSDirectory.open(new File("F:/LuceneDB")); version = Version.LUCENE_30; analyzer = new StandardAnalyzer(version);// analyzer = new IKAnalyzer(); maxFieldLength = MaxFieldLength.LIMITED; } catch (Exception e) { e.printStackTrace(); } } /** * javabean转document * @param obj * @return * @throws Exception */ public static Document javabean2documemt(Object obj) throws Exception{ //创建document对象 Document document = new Document(); //获取字节码对象 Class clazz = obj.getClass(); //获取该对象中的私有属性: 使用强反射 这里使用类全称,防止和Lucene包起冲突 java.lang.reflect.Field[] reflectfields = clazz.getDeclaredFields(); //遍历字段 for (java.lang.reflect.Field field : reflectfields) { //设置访问权限:因为字段是私有的 field.setAccessible(true); String fieldName = field.getName(); //给其拼装成get方法 String methodName = "get" + fieldName.substring(0,1).toUpperCase() + fieldName.substring(1); Method method = clazz.getMethod(methodName, null); //调用方法 String returnValue = method.invoke(obj, null).toString(); document.add(new Field(fieldName, returnValue, Store.YES, Index.ANALYZED)); } return document; } /** * document转javabean,可以使用BeanUtils组件 * @throws Exception */ public static Object document2javabean(Document document,Class clazz) throws Exception{ //先获取字节码对象 Object obj = clazz.newInstance(); //获取到各个字段名 java.lang.reflect.Field[] reflectField = clazz.getDeclaredFields(); for (java.lang.reflect.Field field : reflectField) { //设置访问权限 field.setAccessible(true); //获取各个的字段名和值 String fieldName = field.getName(); String fieldValue = document.get(fieldName); //使用BeanUtils组件封装对象 BeanUtils.setProperty(obj, fieldName, fieldValue); } return obj; } public static Directory getDirectory() { return directory; } public static Analyzer getAnalyzer() { return analyzer; } public static Version getVersion() { return version; } public static MaxFieldLength getMaxFieldLength() { return maxFieldLength; } } 接下来我们创建StudentDao类查询Lucene的记录
package cn.qblank.dao;import java.util.ArrayList;import java.util.List;import org.apache.lucene.document.Document;import org.apache.lucene.queryParser.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.search.highlight.Fragmenter;import org.apache.lucene.search.highlight.Highlighter;import org.apache.lucene.search.highlight.QueryScorer;import org.apache.lucene.search.highlight.SimpleFragmenter;import org.apache.lucene.search.highlight.SimpleHTMLFormatter;import cn.qblank.entity.Student;import cn.qblank.util.LuceneUtil;/** * 持久层 * @author Administrator * */public class StudentDao { /** * 根据关键字,获取总记录数 * @return 总记录数 */ public int getAllRecord(String keywords) throws Exception{ //创建查询器 QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(), "describe", LuceneUtil.getAnalyzer()); //封装查询数据 Query query = queryParser.parse(keywords); IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory()); TopDocs topDocs = indexSearcher.search(query, 2); indexSearcher.close(); //返回符合条件的真实总记录数,不受2的影响 return topDocs.totalHits; //返回符合条件的总记录数,受2的影响 //return topDocs.scoreDocs.length; } /** * 根据关键字,批量查询记录 * @param start 从第几条记录的索引号开始查询,索引号从0开始 * @param size 最多查询几条记录,不满足最多数目时,以实际为准 * @return 集合 */ public List findAll(String keywords,int start,int size) throws Exception{ //用于存储数据 List studentList = new ArrayList (); //创建查询器QuertParser QueryParser queryParser = new QueryParser(LuceneUtil.getVersion(), "describe", LuceneUtil.getAnalyzer()); //封装查询数据 Query query = queryParser.parse(keywords); IndexSearcher indexSearcher = new IndexSearcher(LuceneUtil.getDirectory()); //查询前100条数据 TopDocs topDocs = indexSearcher.search(query, 100); //将查询的结果高亮显示 //创建格式对象 SimpleHTMLFormatter formatter = new SimpleHTMLFormatter(" ", ""); //创建关键字对象 QueryScorer scorer = new QueryScorer(query); //创建高亮对象 Highlighter highlighter = new Highlighter(formatter, scorer); //代表显示的字的个数 /*Fragmenter fragmenter = new SimpleFragmenter(4); highlighter.setTextFragmenter(fragmenter);*/ //进行分页 //获取查询的页数 int middle = Math.min(start + size, topDocs.totalHits); for (int i = start; i < middle; i++) { ScoreDoc scoreDoc = topDocs.scoreDocs[i]; //获取编号 int no = scoreDoc.doc; //查询编号对应的document对象 Document document = indexSearcher.doc(no); //高亮显示 //关键字高亮显示 String highlighterDescribe = highlighter.getBestFragment(LuceneUtil.getAnalyzer(), "describe",document.get("describe")); //String highlighterName = highlighter.getBestFragment(LuceneUtil.getAnalyzer(), "name",document.get("name")); //将标题和内容高亮 document.getField("describe").setValue(highlighterDescribe); //document.getField("name").setValue(highlighterName); //将document对象转换为javabean Student student = (Student) LuceneUtil.document2javabean(document, Student.class); //将查询出来的数据添加到集合中 studentList.add(student); } indexSearcher.close(); return studentList; }} 然后写好StudentService将查询到的数据进行逻辑判断,并将相应的数据封装到Page对象中
package cn.qblank.service;import java.util.List;import cn.qblank.dao.StudentDao;import cn.qblank.entity.Page;import cn.qblank.entity.Student;/** * 业务层 * @author Administrator * */public class StudentService { private StudentDao studentDao = new StudentDao(); /** * 通过关键字查询内容 * @param keywords 关键字 * @param currPageNO 当前页号 * @throws Exception */ public Page show(String keywords,int currPageNO) throws Exception{ Page page = new Page(); //封装当前页号 page.setCurrPageNO(currPageNO); //封装总记录数 int allRecordNO = studentDao.getAllRecord(keywords); page.setAllRecordNO(allRecordNO); //封装总页数 int allPageNO = 0; if (page.getAllRecordNO() % page.getPerPageSize() == 0) { allPageNO = page.getAllRecordNO() / page.getPerPageSize(); }else{ allPageNO = page.getAllRecordNO() % page.getPerPageSize() + 1; } //封装总页数 page.setAllPageNO(allPageNO); //封装内容 Integer size = page.getPerPageSize(); Integer start = (page.getCurrPageNO() -1 ) * size; List studentList = studentDao.findAll(keywords, start, size); page.setStudentList(studentList); return page; }} 然后写好EasyUI优化过的list.jsp的页面,然后将输入的关键字异步方式传入到后台
<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%><%String path = request.getContextPath();String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";%>使用Jsp +Js + JQuery + EasyUI + Servlet + Lucene完成分页
package cn.qblank.action;import java.io.IOException;import java.io.PrintWriter;import java.util.LinkedHashMap;import java.util.Map;import javax.servlet.ServletException;import javax.servlet.http.HttpServlet;import javax.servlet.http.HttpServletRequest;import javax.servlet.http.HttpServletResponse;import net.sf.json.JSONArray;import cn.qblank.entity.Page;import cn.qblank.service.StudentService;@SuppressWarnings("serial")public class StudentServlet extends HttpServlet { @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { this.doPost(req, resp); } @Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { resp.setContentType("text/html;charset=utf-8"); try { //获取关键字 String keywords = req.getParameter("keywords"); //如果为空,给默认值 好 if (keywords == null || keywords.trim().length() == 0) { keywords = "好"; } //获取当前页号 EasyUI固定写法获取页号 String currPage = req.getParameter("page"); if (currPage == null || currPage.trim().length() == 0) { currPage = "1"; } //调用Service StudentService studentService = new StudentService(); Page page = studentService.show(keywords, Integer.parseInt(currPage)); //构造Map对象 Map map = new LinkedHashMap<>(); //将总页数和查询的结果列表存入Map集合中 map.put("total", page.getAllRecordNO()); map.put("rows", page.getStudentList()); //将集合转为JSON对象 JSONArray jsonArray = JSONArray.fromObject(map); //转换为java的字符串格式 String jsonJAVA = jsonArray.toString(); //去掉俩边的[] jsonJAVA = jsonJAVA.substring(1,jsonJAVA.length() - 1); //使用O流打印出去 PrintWriter pw = resp.getWriter(); pw.write(jsonJAVA); pw.flush(); pw.close(); } catch (Exception e) { e.printStackTrace(); } }} 事先我已经放入5调数据到Lucene库中,添加的代码可以看我的上篇博客 http://blog.csdn.net/evan_qb/article/details/78512216
接下来我们运行下,看下结果


你可能感兴趣的文章
Java Guava中的函数式编程讲解
查看>>
Eclipse Memory Analyzer 使用技巧
查看>>
tomcat连接超时
查看>>
谈谈编程思想
查看>>
iOS MapKit导航及地理转码辅助类
查看>>
检测iOS的网络可用性并打开网络设置
查看>>
简单封装FMDB操作sqlite的模板
查看>>
iOS开发中Instruments的用法
查看>>
iOS常用宏定义
查看>>
被废弃的dispatch_get_current_queue
查看>>
什么是ActiveRecord
查看>>
有道词典for mac在Mac OS X 10.9不能取词
查看>>
关于“团队建设”的反思
查看>>
利用jekyll在github中搭建博客
查看>>
Windows7中IIS简单安装与配置(详细图解)
查看>>
linux基本命令
查看>>
BlockQueue 生产消费 不需要判断阻塞唤醒条件
查看>>
ExecutorService 线程池 newFixedThreadPool newSingleThreadExecutor newCachedThreadPool
查看>>
强引用 软引用 弱引用 虚引用
查看>>
数据类型 java转换
查看>>